The Ungreen Web: Why Our Web Apps Are Terribly Inefficient?

Even though Amazon’s example isn’t unique in the context of this post, I’ll use it as a first example of efficiency of a modern web service:

Fetching an HTML of a product page on Amazon — even if you did the same just a fraction of second ago (so nothing really changed), requires 1.3 seconds. And that’s on 1000Gbps AT&T Fiber + WiFi 6 in Los Angeles:
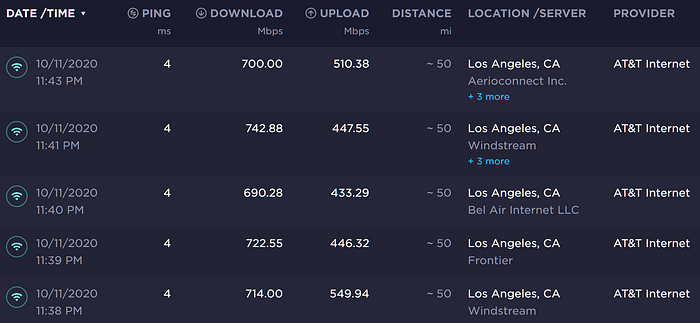
Amazon servers spend 1.3 seconds to “render” and send you ~ 1MB of text (209KB compressed), or ~ 773KB / second. How good this result is?
I know it’s totally not apples-to-apples comparison, but I still want to illustrate how small this number is:
- An FPS game rendering ~ 130 frames per second in 4K = 30*3840*2160*10 = 10,782,720 KB / second of pixel data, assuming it uses 2 bytes per channel + 4-byte depth buffer.
- 10,782,720 / 774 = 13,931 — that’s the number of bytes such FPS game produces while Amazon generates a single letter of text on its web page.
- And even if you take into account the fact every web server handles 10 … 100 of such requests simultaneously, the difference still looks staggering.
Amazon is totally not unique in this sense:
- eBay timings are a bit better, but still, it’s 0.6s to respond to a page refresh.
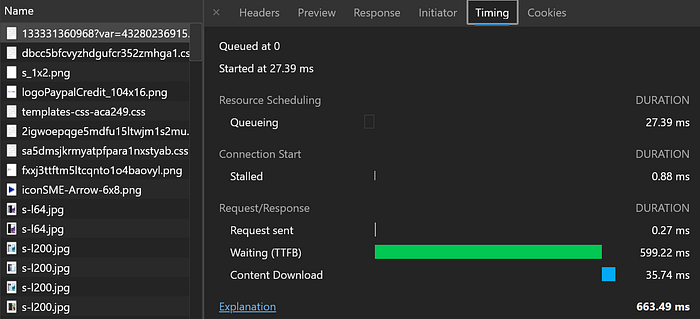
2. Twitter is also consistent in spending 0.1 … 0.5s on repeated API requests:
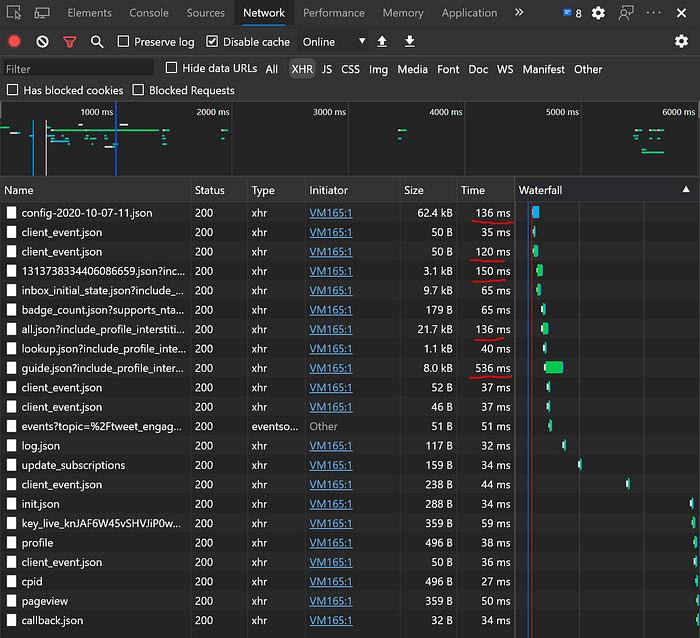
3. Medium needs ~ 1 second to send you the very first byte of ~ 40KB response — again, to repeated request to a specific post’s page:
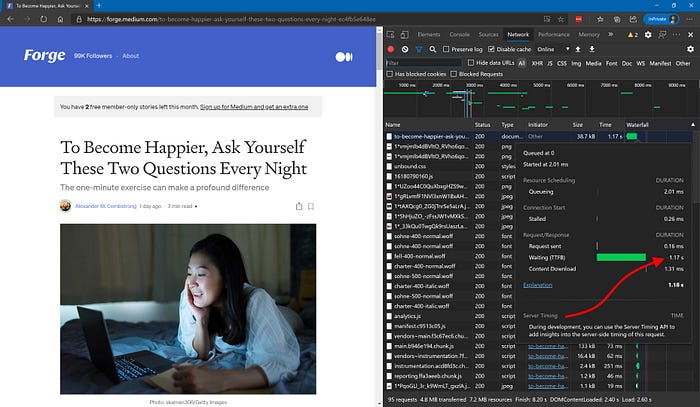
4. SaaS services increases these timings even further. Check out e.g. GitHub. Based on my own experience, action-to-reaction time of 2…4 seconds is more or less normal in SaaS world. Not every action, of course, but for some (even the frequent ones) — absolutely.
5. Facebook is the only exception among top-tier websites: it responds in ~ 60ms on most of repeated API requests for not-so-popular content, and my guess is that it definitely solves the problem I describe further. But even its result seems challengeable: my ping time to facebook.com is ~ 4ms, so it spends ~ 55ms to respond, and this is actually still a lot, if you know that just a few moments ago almost identical response was already computed, which means you probably need just a few milliseconds to hit the cache & recompute what’s changed.
Why am I certain there is a room for performance improvements?
I am one of people who spent most of my life building either web services or their components. And the more I think about how web services work, the more it becomes obvious we don’t do it right.
If you’re developer, here is an example you should be familiar with: incremental builds. Most of us use them, sometimes even without noticing. Here is how they work:
- The build system tracks dependencies (usually — files and other artifacts) needed to produce every build artifact
- Once one of dependencies changes, the artifact that depends on what’s changed becomes marked as “inconsistent” (needs a rebuild), as well as any other build artifact dependent on it. So once the build is triggered, only the inconsistent artifacts are re-built. The rest is simply re-used.
- And since developers rarely change everything at once, usually a tiny subset of all artifacts are rebuilt on each subsequent build.
More sophisticated build systems track dependencies more granularly. E.g. some compilers nowadays cache abstract syntax trees (ASTs) for your files and even pre-compiled code, so in the end, they don’t even fully compile the impacted modules while building your project.
And as you might guess, the larger your project is, the more you win from incremental builds.
Some examples of huge ecosystems relying on incremental builds include:
- Docker. As you know, container images are ~ diffs to base images. When you build a docker container for your app, you typically use images built by someone else and stored in one of docker image repositories.
- Software package repositories — in particular, NuGet for .NET or PyPI for Python. Once a package is built & stored on one of these repositories, you (or your compiler) can simply download & use it.
Wait, but how incremental builds are related to web services?
It’s fairly simple:
Most of web apps nowadays generate the content of every page and every API response ~ almost from scratch. Yes, they do ~ the same job every time you request a piece of content.
In other words, most of web services don’t use something similar to incremental builds to build the output. They simply rebuild everything every time you ask.
Here is how a typical API request gets processed:
- The middleware stack parses misc. parts of request, but in the end, it hits the controller.
- The controller calls one or more services. In many cases these services are clients of remote microservices, so ~ the same chain “extends” to the actual microservices, and microservices behave similarly.
- The actual service hits the underlying storage — usually, a database. In some it hits the cache, but this option is typically used only when nothing else helps — because cache invalidation is complex. That’s also why caches are typically used only at the very beginning of request processing pipeline: implementing real-time cache invalidation logic based on changes in data is hard, so developers tend to implement such logic for the smallest subset of API calls possible.
- As a result, even if there is a cache, the miss implies that not only the result, but every intermediate value will be recomputed — and as you might guess, most of API endpoints powering e.g. UIs are returning aggregates.
- And if there is no cache — it’s always a full recompute, in other words, the service producing the result of this API call will end up hitting DB a few times to pull all the intermediates, etc., etc.
This is why you frequently see ~ a 10ms response time for a majority of “resource” requests — they are easy to cache. Similarly, 100ms…1s response time is normal for API or “data” requests — they are hard to cache, and so they are frequently recomputed from scratch.
Think about this:
- Do you believe there is enough of unique content on Amazon or eBay product page shown only to you so that the page can’t be computed in 0.01s, assuming we consider “uniqueness” across all other users visiting the site over last several minutes?
- Same is true about the Medium post page, tweet / tweet thread, etc. — they contain just a few hundred lines of text, 99% of which is identical for everyone else.
So how could it happen that servers need ~ 1s to produce such pages?
The problem statement
What our servers do during the seconds they spend on a single request? Mostly, they recompute the same values again and again. In fact, they recompute “temporary constants” — values that are known to stay the same, because every “ingredient” used to produce them is still the same.
Why do they recompute “temporary constants”? Ultimately, because they don’t have a good way to track the “ingredients” and know once they get changed, so they pessimistically assume the ingredients differ each time you need a value that uses them.
What should they do instead? Start tracking dependencies and recompute only what’s changed or evicted from caches due to memory constraints. For the sake of clarity, it’s not just about the API response-level caching — it’s about the intermediates. Think of incremental builds: would it help to cache just the final output knowing any tiny change will invalidate it? But that’s roughly where we are.
This is why I ended up adding “The Ungreen Web” to the title: “one oft-repeated claim is that the world’s data centers emit as much CO2 as the global aviation industry (Pearce 2018)”, and even though this claim was arguable a year ago, the growth rate of cloud compute workloads (~ 10x over 10 years) and, sadly, COVID-19 might already render it valid. And as you might guess, the potential for energy efficiency improvements here is way higher than for the aviation industry.
How we ended up in this state?
Interestingly, it’s very natural:
- Most of companies start to care about the performance only when it becomes too expensive to disregard it. This is why performance is crucial for e.g. FPS games (you simply won’t sell a game rendering a few frames per second), but not so crucial for web apps — assuming sub-second response time is still perceived as “good enough”.
- Above is especially valid for web startups: product first, bells and whistles later, and performance is usually one of such whistles.
- Interestingly, the larger you are, the more pronounced the problem becomes. Would you be willing to continue spending 3–5x on servers and be 10x slower knowing that your cloud infrastructure consumes 10% of your overall expenses? For the note, cloud and social startups tend to have higher server costs, so e.g. for Twitter it’s ~ 35% of total costs and expenses. But dependency tracking is something that’s much easier to address in the beginning rather than later, i.e. the easiest way to save these 10x is to plan this in advance.
- Caching with robust dependency tracking is a presumably hard problem. Try to google it to see how see the solution landscape looks, but overall, so far there were no simple, plug-and-play solutions that “just do it”; nearly all available solutions complex and prohibitively costly from dev cost perspective.
- We’ve got used to Moore’s law.
A fancy evidence proving some of these points: there is a plethora of solutions for caching, but almost zero for dependency tracking.
Wikipedia doesn’t seem to have even a list of such products, even though solving dependency tracking problem is crucial for cache invalidation: it boosts cache efficiency by allowing items to be cached for as long as needed (or possible) assuming the invalidation will inevitably happen at the right moment, but more importantly, it also makes an eventually consistent system practically almost as good as a strongly consistent one.
So if you know how deep is the connection between these two problems, that’s how caching without dependency tracking should look for you:

But seriously, what’s wrong with timeout-based expiration?
Let’s use incremental builds to show the difference:
- No caching: rebuild everything on every run
- Timeout-based response caching: no matter how frequently you make changes, you run an outdated build for at least T minutes, and once they’re gone, you’ll need to wait for a complete rebuild
- Response caching & real-time cache invalidation: rebuild everything once something changes, otherwise run the prev. build — in other words, it’s ~ non-incremental build, but no rebuild on run if nothing has changed.
- Dependency tracking-based cache invalidation: incremental build & run.
Are there any solutions?
AFAIK, there are none — at least no even moderately known ones, assuming we are talking about generic dependency tracking libraries you can plug to your own code.
More precisely, there were none. I’m the author of Fusion — an open-source library for .NET Core trying to change the way we build real-time web apps. Everything it does is based on a single core feature: transparent dependency tracking for the result of any computation you want. This allows Fusion to solve a number of higher-level problems, including the ability to deliver real-time updates to any value to remote clients and ~10-fold improvement in response time and server efficiency.
Earlier I gave “an order of magnitude” estimate of potential efficiency gains for web apps, and Fusion’s Caching Sample actually proves you can expect similar gains for your services:
- Fusion used only on server-side boosts the performance of an extremely simple ASP.NET Core API endpoint with a fully cacheable data set from 20,000 to 110,000 requests per second. So ~ 5x performance and efficiency boost is probably the minimum you should expect, because the more complex your service is, the higher is the expected gain from caching.
- But once dependency tracking is extended to the client, the dependency-aware client (“Replica Service” in Fusion’s terms) scales to 22,000,000 (!) request per second — and that’s on a single machine!

Further Readings
If you found the post interesting and want to learn more about Fusion and some other problems it solves, check out my other posts:
- Real-Time is #1 Feature Your Next Web App Needs
- How Similar Is Fusion to SignalR?
- How similar is Fusion to Knockout / MobX?
- Fusion In Simple Terms
- The Story Behind Fusion
And finally, check out Fusion repository on GitHub and its samples.
About the author
If you’re using .NET for a while, you might also know me as a creator of one of the first commercial ORM products for .NET (DataObjects.NET). In past, I worked on site performance at Quora, Inc., where I wrote the initial version of asynq library. Currently I’m the CTO at ServiceTitan, Inc. — the world’s leading all-in-one software for residential and commercial service and replacement contractors.
I love building tools helping developers to tackle otherwise challenging problems. And the problem I highlighted in this post is clearly of this kind: potential 10x performance improvement is too good to disregard + knowing there are no well-known solutions means that probably everyone else who tried didn’t manage to produce something that’s good enough for a majority of developers. This was motivating enough for me to build Fusion and try to make a dent in web app efficiency area :)
P.S. If you find this post useful — even if you aren’t on .NET, please re-share. And if you are on .NET, tweeting the link to this post would be greatly appreciated!